A cura del Settore orientamento e informazioni bibliografiche
Biblioteca 2.0
Web semantico e Linked Open Data
 A corredo degli articoli che questo numero di MinervaWeb dedica - nella sezione Eventi - al recente dibattito su Web Semantico e Linked Open Data, riceviamo e volentieri ospitiamo il contributo di Chiara Galimberti (Albano Laziale, 1985), che lavora in Lussemburgo presso La Libreria Italiana e che nel luglio 2013 ha discusso presso l'Università di Roma Tre una tesi magistrale dal titolo 'Collezioni digitali in rete: questioni descrittive e prospettive del Web Semantico'. Una sintetica e lucida introduzione, di facile lettura, ai nuovi modelli delle informazioni in rete, che ci guida nella storia recente e nelle prospettive future del Web.
A corredo degli articoli che questo numero di MinervaWeb dedica - nella sezione Eventi - al recente dibattito su Web Semantico e Linked Open Data, riceviamo e volentieri ospitiamo il contributo di Chiara Galimberti (Albano Laziale, 1985), che lavora in Lussemburgo presso La Libreria Italiana e che nel luglio 2013 ha discusso presso l'Università di Roma Tre una tesi magistrale dal titolo 'Collezioni digitali in rete: questioni descrittive e prospettive del Web Semantico'. Una sintetica e lucida introduzione, di facile lettura, ai nuovi modelli delle informazioni in rete, che ci guida nella storia recente e nelle prospettive future del Web.
*******************
1. Introduzione: motivazioni alla base della nascita del Web Semantico
2. Il Web Semantico: uno strumento per raffinare le ricerche su Internet
3. I Linked Open Data al servizio del Web Semantico
4. Possibili applicazioni dei Linked Open Data
6. Riferimenti e approfondimenti bibliografici
*******************
1. Introduzione: motivazioni alla base della nascita del Web Semantico
La crescita vertiginosa dell'oceano informativo raggiunta in breve tempo dal Web deriva dalla condizione primaria per cui il Web stesso è stato pensato, ovvero la libertà di pubblicazione da parte di chiunque voglia inserire un testo, un video oppure documenti di ogni tipo, più o meno attendibili e verificati. Una grande libertà che si è però trasformata anche nel suo limite intrinseco, poiché causa spesso lo smarrimento degli utenti di fronte a tale mole di informazioni e che soprattutto ha reso più complicato il reperimento di informazioni precise tra la moltitudine di quelle disponibili.
Fino ad oggi gli utenti hanno attinto le informazioni richieste da un 'Web di Documenti', il metodo tradizionale per l'identificazione dei contenuti, fondato sull'utilizzo delle 'parole chiave'. Paragonabile a un grande bloc-notes, tale sistema archiviava le informazioni presentandole in modo lineare e ordinato, ma in forma piatta e statica che non permetteva la possibilità di movimento e di connessione tra le informazioni stesse. Solo l'uomo poteva sopperire alla staticità di tali dati creandone connessioni ed elaborando nuova conoscenza, in quanto il processo di combinare informazioni, anche se incomplete o provenienti da fonti eterogenee e memorizzate in formati diversi, è ragionevolmente semplice, anche se talvolta noioso e/o ripetitivo.
La necessità di superare la limitatezza del 'Web di Documenti' ha portato alla ricerca di un nuovo sistema in grado di permettere anche alle macchine di combinare automaticamente la conoscenza proveniente dalle diverse fonti ed, ancor meglio, da queste derivarne di nuova. E' qui che entrano in gioco, pertanto, il Web Semantico e i Linked Open Data.
*******************
2. Il Web Semantico: uno strumento per raffinare le ricerche su Internet
Il Web Semantico (secondo la fortunata espressione coniata alla fine degli anni '90 e diffusa dal W3C- World Wide Web Consortium, che si occupa di promuovere standard per l'interoperabilità del Web) ambisce a trasformare il 'Web di documenti' in un 'Web di dati' , costituito da "oggetti" concreti ed elaborabili dalle macchine (machine understandable). Si tratta di fornire ai calcolatori la capacità di combinare i dati per creare nuova conoscenza, formare nuove connessioni e trarre nuove conclusioni partendo dai dati indicizzati, automatizzando ciò che era finora appannaggio esclusivo dell'uomo. Tutto ciò è divenuto possibile perché il Web Semantico è basato sulla comprensione del significato dei termini.
Un piccolo esempio può rendere più chiaro il concetto: per come è organizzato attualmente il Web, se lo si interroga per mezzo di un comune motore di ricerca sulla parola 'albero', si otterranno risultati inerenti alla botanica (intendendo albero come pianta), alla nautica (albero della nave), alla meccanica (albero di trasmissione), all'informatica (albero come struttura di dati) e magari il collegamento alla trasmissione televisiva L'albero azzurro o al nome di un ristorante. Questo accade poiché nel Web la parola 'albero' usata come chiave della ricerca non è necessariamente collegata al contesto. Se invece, al momento dell'inserimento in internet del termine 'albero', gli dessimo informazioni aggiuntive, etichettandolo (taggandolo) ad esempio con la parola 'vegetale', otterremo dalla nostra ricerca solamente informazioni sul mondo vegetale rendendola quindi più diretta, pertinente e rilevante.
Al momento dell'indicizzazione di un termine sulla rete, pertanto, dovrà anche essere inserita tutta una serie di metadati (vedi Glossario - FARE LINK) riferiti ad esso, che creeranno una sorta di maglia, una fitta griglia di informazioni pertinenti al dato stesso. Il Semantic Web può quindi essere definito un'infrastruttura basata su metadatiper svolgere ragionamenti sul Web.
Il Web Semantico non nasce, dunque, con lo scopo di sostituire il Web tradizionale, bensì per estenderne il potenziale, realizzando quanto il noto informatico britannico Tim Berners-Lee (ideatore, insieme a Robert Caillau, del World Wide Web) descrive come un mondo in cui "i meccanismi quotidiani del commercio, della burocrazia, e delle nostre vite quotidiane saranno gestiti da macchine che interagiscono con altre macchine, lasciando agli umani il compito di fornire l'ispirazione e l'intuizione" (Tim Berners-Lee, L'architettura del nuovo Web, 1999). Il 'Web di dati' è pertanto la naturale evoluzione del 'Web di documenti'.
*******************
3. I Linked Open Data al servizio del Web Semantico
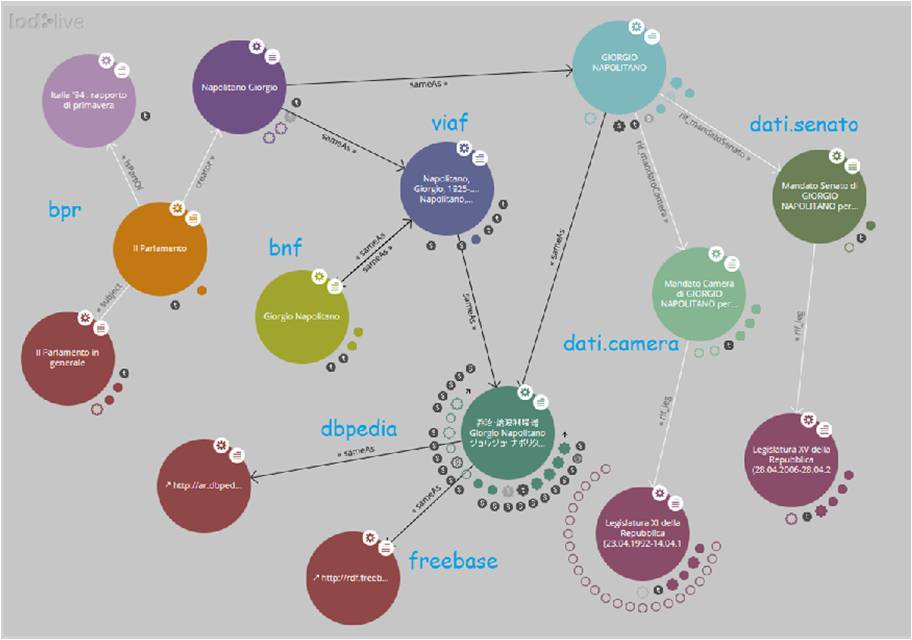
Se il Web Semantico è l'obiettivo finale da perseguire, i Linked Data rappresentano il mezzo per raggiungerlo. Il paradigma Linked Data è un insieme di buone regole per la pubblicazione dei dati sul Web che permette alle macchine di individuarli facilmente, di incrociarli e manipolarli, per questo i dati vengono chiamati 'dati strutturati o collegati', ovvero Linked Data. Tra i principi suggeriti dallo stesso Tim Berners-Lee per la pubblicazione e la connessione di dati strutturati sul Web, accenniamo ad esempio all'utilizzo di identificatori univoci della risorsa di rete (URI - Uniform Resource Indicator) anziché di semplici localizzatori temporanei quali sono gli URL (Uniform Resource Locator), ma comunque preceduti da 'http://' perché sia possibile accedervi tramite il più diffuso protocollo di comunicazione in rete; al collegamento degli URI con altri URI; al ricorso a standard condivisi come RDF (Resource Description Framework) per il data model e SPARQL per l'interrogazione dei Linked Data.
Allo scopo di rendere i Linked Data completamente accessibili al mondo del Web è necessario che vengano pubblicati sotto condizioni d'uso 'aperte' o 'libere' ('Open'), che ne consentano consultazione, navigazione e aggregazione. Ciò diviene possibile se i Linked Data sono contemporaneamente:
- Aperti: ai Linked Data si accede attraverso una varietà illimitata di applicazioni poiché sono espressi in formati non proprietari;
- Modulari: i Linked Data possono essere combinati con altri Linked Data (ad esempio, i dati sulle spese sanitarie della pubblica amministrazione di un'area geografica possono essere combinati con altri dati relativi alle caratteristiche della popolazione della stessa regione, per verificare l'efficacia delle politiche amministrative);
- Scalabili: il termine scalabilità si riferisce, in termini generali, alla capacità di un sistema di 'crescere' o 'decrescere' (aumentare o diminuire di scala). Aggiungere nuovi Linked Data a quelli esistenti è semplice anche quando i termini e le definizioni utilizzati cambiano nel tempo.
Il valore dei dati, minimo se questi si presentano isolati, aumenta sensibilmente quando differenti archivi, detti anche dataset, possono essere incrociati o aggregati liberamente dal fruitore. Uno dei vantaggi principali dei Linked Open Data è quindi l'interoperabilità tra i dati stessi. Il desiderio degli studiosi è la creazione di un unico grande database distribuito: uno spazio di dati collegati tra loro all'interno del quale utenti e applicazioni software possano muoversi agilmente, saltando da un dataset all'altro, scoprendo nuove informazioni e (nel caso di dati open) collezionandole e ripubblicandole liberamente. I Linked Open Data si presentano sotto forma di 'triple', ovvero asserzioni di tipo soggetto-predicato-oggetto. A loro volta le triple possono esser combinate per dedurre automaticamente nuova conoscenza. Il seguente esempio può chiarire il concetto:
- Chiara è figlia di Marco;
- Flavia è figlia di Marco;
- Marco è figlio di Angelina.
Tre semplici proposizioni accolte come vere, da cui è possibile ricavarne almeno altre tre, seppur non esplicitate da triple:
- Chiara e Flavia sono sorelle;
- Marco è padre;
- Angelina è nonna di Chiara e di Flavia.
Il meccanismo alla base dell'elaborazione di tali asserzioni viene definito inferenza: processo con il quale da una proposizione accolta come vera, si passa a una seconda proposizione la cui verità è dedotta dal contenuto della prima. Con tale operazione ogni nuova asserzione, espressa in forma di tripla, diventa a sua volta generatrice di nuova informazione. E tale è proprio il principio alla base del Web Semantico: dedurre nuova conoscenza elaborando dati noti.
*******************
4. Possibili applicazioni dei Linked Open Data
Il 22 febbraio scorso si è svolta in alcune città italiane la quarta edizione dell'International Open Data Day, che raduna cittadini di tutto il mondo impegnati a scrivere applicazioni, liberare i dati, creare visualizzazioni e pubblicare analisi utilizzando dati pubblici aperti. La finalità alla base dell'organizzazione di tale iniziativa è quella di sostenere e incoraggiare le politiche di adozione dei dati aperti da parte dei governi locali, regionali e nazionali in tutto il mondo. Il W3C, in prossimità dell'evento, ha organizzato un convegno a Roma per condividere le informazioni sugli ultimi sviluppi del mondo Web per quanto riguarda i Linked Open Data. Tra le varie applicazioni dei Linked Open Data proposte (dettagliate nell'articolo Convegno LOD2014 - FARE LINK - in questo stesso numero di MinervaWeb - FARE LINK) suscitano particolare interesse le iniziative volte ad "aprire" e strutturare secondo l'architettura del Web semantico i dati delle amministrazioni e degli organi costituzionali. Sarebbe utile riflettere, infatti, su quanto la nostra influenza e la nostra partecipazione alla società aumenterebbero ogni giorno se noi potessimo verificare la validità dei procedimenti legislativi e quali enormi vantaggi potremmo ricavare dalla disponibilità, dalla trasparenza e dal facile accesso ai dati di ogni tipo.
*******************
In conclusione si può affermare che le aspettative in relazione allo sviluppo del Web Semantico tramite l'utilizzo dei Linked Open Data siano quelle di ridurre al minimo la separazione tra discovery (individuazione della notizia bibliografica) e delivery (reperimento del documento) e di creare un ecosistema di metadati che diventi opportunità di condivisione, pubblicità, interoperabilità tecnica e semantica dei metadati stessi, per una gestione quanto più possibile integrata delle risorse informative. Oltre a potenziare l'efficacia e la visibilità delle informazioni disponibili in rete, si spera che tali pratiche possano permettere, in un futuro quanto mai prossimo, anche una disponibilità globale dei dati (legislativi, amministrativi, bibliografici ecc.) all'interno di un più vasto quadro di apertura e di interconnessione di informazioni.
*******************
6. Riferimenti e approfondimenti bibliografici
Web semantico e Linked Open Data. Percorso bibliografico nelle collezioni della Biblioteca. Si suggerisce inoltre la ricerca nel Catalogo del Polo bibliotecario parlamentare e nelle banche dati consultabili dalle postazioni pubbliche della Biblioteca.